- A+

元宇宙时代已经来临,当你看到网络新闻上形形色色的虚拟人的时候,是不是有些心动?你是否认为创造虚拟人需要很大的学习成本和技术投入,普通开发者单枪匹马根本无法办得到?现在这些都不再是问题,飞桨预训练模型应用工具PaddleHub助你快速实现!
文章指路:</2021><2022>今天,陪我一起过节吧!
这个虚拟数字人给大家的新年祝福大家应该看过了,今天给大家做一个技术详细揭秘。
背后支持虚拟数字人的“神秘力量”,其实是飞桨强大的开源生态和AI能力。
飞桨语音模型库PaddleSpeech将文字转换成语音,让虚拟数字人有了自己的声音。飞桨生成对抗网络开发套件PaddleGAN的人脸生成能力赋予了虚拟数字人一张可爱的脸蛋,表情迁移、唇形合成(同步)等模型驱动虚拟数字人的脸部活动,让虚拟人更加栩栩如生。
目前PaddleHub已经把以上模型纳入了模型库当中,现在只需要通过简单的十几行代码调用模型,输入图片和文字,即可生成一个生动形象的虚拟数字人。
技术原理
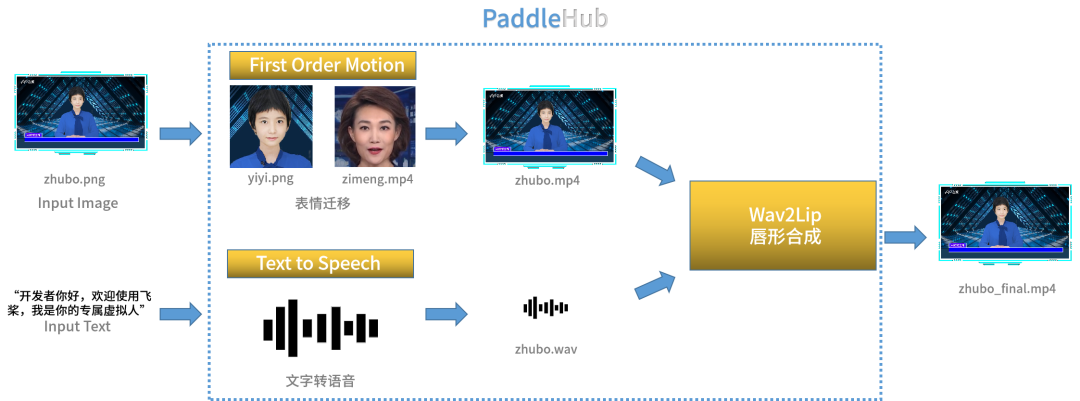
生成虚拟数字人总共需要调用三个模型,分别是First Order Motion(表情迁移)、Text to Speech(文本转语音)和Wav2Lip(唇形合成)。
实现步骤
1.把图像放入First Order Motion模型实现面部表情迁移,让虚拟主播的表情更加逼近真人。
-
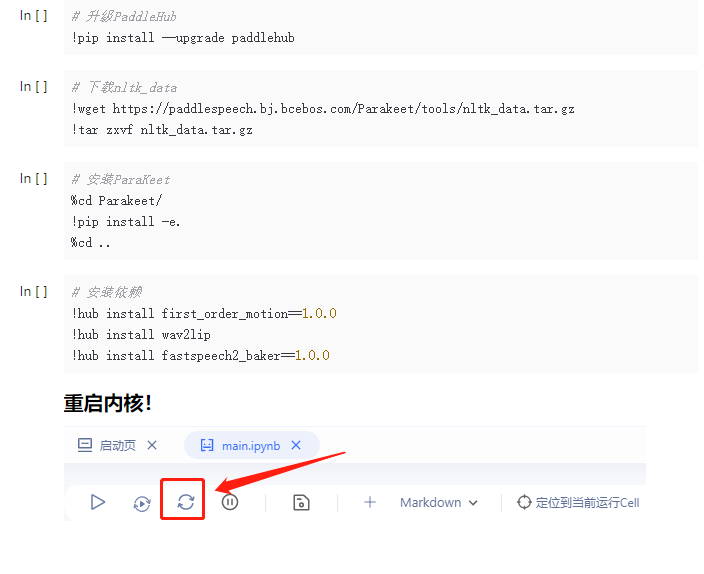
依赖安装
-
图像准备
首先需要准备一张带背景和人脸的二维静态图像,如图所示。

-
表情迁移
通过FOM模型,输入图像和驱动视频,让人像动起来。

2.输入你想让数字人说的话,通过Text to Speech模型,将输入的文字转换成音频输出。

3.得到面部表情迁移的视频和音频之后,将音频文件和动态视频输入到Wav2Lip模型,并根据音频内容调整唇形,让唇形根据说话的内容动态改变,使得虚拟人更加接近真人效果。

经过上面的三个步骤,一个虚拟数字人的视频就生成了。
高阶玩法
PaddleBoBo是飞桨社区开发者基于飞桨框架和PaddleSpeech、PaddleGAN等开发套件的虚拟主播快速生成项目。除了可以实现以上功能之外,同时还支持调整语速、音高等,更可以经过简单的二次开发,实现实时新闻生成、直播播报等,欢迎大家体验和一键三连!
Github:https://github.com/JiehangXie/PaddleBoBo同时也欢迎感兴趣的大佬加入,共同打造飞桨元宇宙!
虚拟数字人的实现离不开飞桨开源生态的努力,希望大家给下面优秀的开源项目点star⭐
⭐ PaddleGAN:https://github.com/PaddlePaddle/PaddleGAN
⭐ PaddleSpeech:https://github.com/PaddlePaddle/PaddleSpeech
⭐ PaddleHub:https://github.com/PaddlePaddle/PaddleHub
END
觉得不错,请点个在看呀