- A+
一个外国人讲着一口流利的中文方言。不知道大家有没有看过这样的视频。
还有郭德纲用英文讲相声。
这类视效果娱乐效果拉满而且毫无PS痕迹。表情,嘴型,声音都毫无违和感。毫无疑问这都是AI的功劳,而且实现方法并不复杂,具体实现可以去看raskai和heygen。

这些产品已经做得很不错,只需要上传一段视频和语音,就可以很快制作类似的视频,有需要的可以直接用。
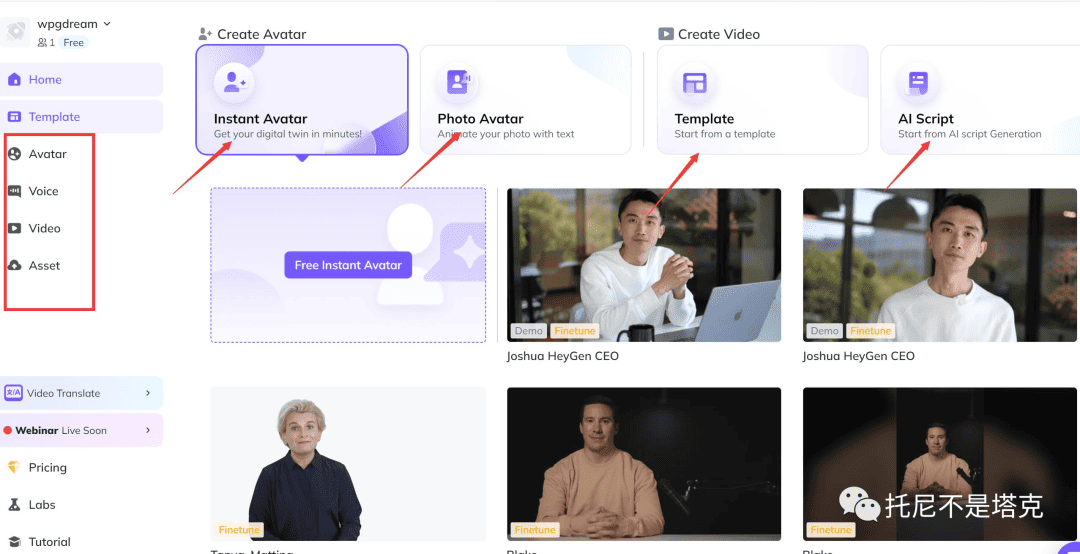
但是这些不是免费的,长期用的价格还不算便宜。另外一个问题是,好多人因为英文和翻x的问题,也是没法上手这类AI产品。
所以有人就想起来“平替” 这个东西。最近好几个人问我能不能搞一下MyHeyGen 这个项目。
好的,那我们就来搞一搞。
这个项目是很多开源项目的整合,涉及到了HeyGenClone、TTS、Video-retalking、CodeFormer 等项目,光模型文件就有十几个。所以要把这个项目搞起来,要了解的东西还挺多。除了这些开源项目之外,还涉及到了一些在线平台的调用。
总的来说,搞起来还是要点力气的!
好处是,搞起来之后几乎可以零成本制作视频。
先来看下官方文档中的步骤。
-
准备一张高配显卡,比如3090,4090等(官方建议显存>24GB)
-
注册huggingface并申请token
-
申请百度翻译APPkey
-
获取18个模型。
-
安装依赖配置运行
因为文档里面没有说支持Windows, 所以我就不敢在Windows上运行,怕坑太多。所以我的计划是在阿里云的深度学习平台或者谷歌的深度学习平台Colab上运行。
由于模型文件都在谷歌网盘上,而且文件比较大,上传到阿里会是一个非常麻烦的事情,所以我就选择Colab平台。
配置过程,踩了一些坑,但是最终还是整成功了。
今天写文章的时候又运行了一遍,然后....出错了!

沃日啊!上次好端端的,这次又挂了。
错误提示肯定是牛头不对马嘴,答案往往很简单,但是你肯定折腾半天。
最后发现是TTS版本问题,上次也是有问题,还专门指定了版本,这次又不行了,得改回去。所有的在线依赖都是这个毛病,明明调好了,别人一动,又挂了。
重新调整了TTS版本之后,Numpy又不高兴了,万幸,浪费了半天时间后还是搞定了。
下面就完整的说一下如何把这个项目跑起来。
首先,我这里使用了Colab平台,所以你的4090可以省下了。
然后,HF和百度翻译的接口还是少不了。
最后,所有复杂的东西都不用不用大家关心了,只要使用我提供的脚本就可以了。
1.注册HF并获取秘钥
huggingface 是一个非常知名的在线AI模型库,他们还搞出了知名的Transformers库,现在的大语言模型基本都会用到这个库。
注册和登录这种常规操作我就不说了。主要说一下如何获取密钥(Token)
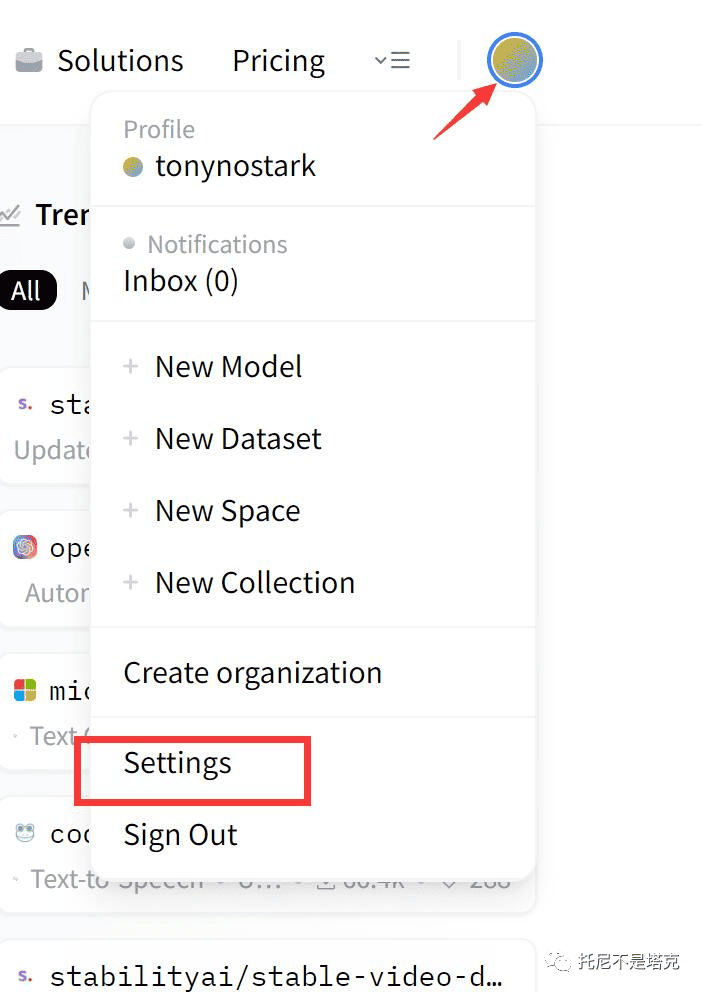
点击右上角的头像,在下拉菜单中点击设置(Settings)
然后
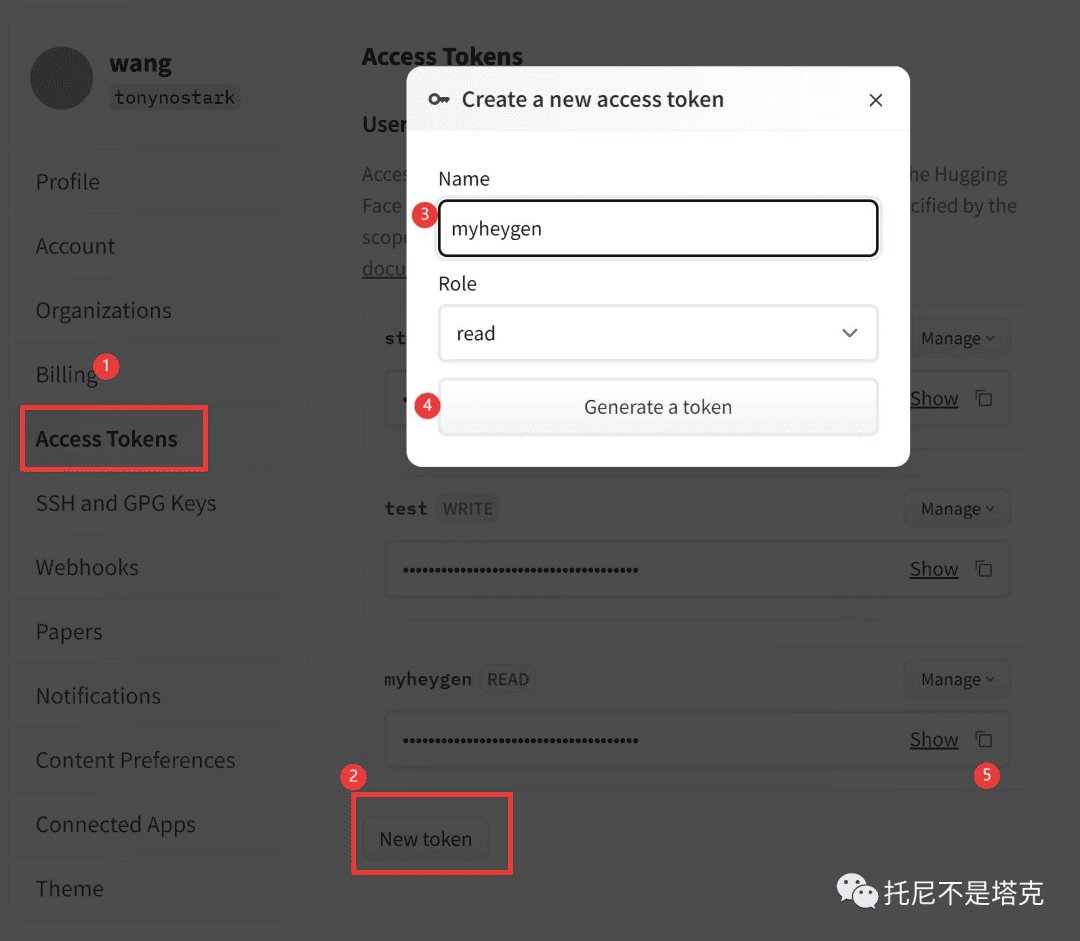
①点击 Access Tokens菜单
②点击Newtoken按钮
③输入Name,可以随便写
④点击Generate a token 生成一个密钥
⑤点击复制图标,复制密钥并保存在记事本里。
这个密钥我们后面要用到。这一步没有难度,只是很不幸,这个网站在国内已经404了。这个问题你们都懂,自己解决就好了。(大部分人应该能熟练解决这个问题了吧)。
另外有一个重点提示,获取HF密钥后主要是为了调用它上面的模型,而这些模型之所以要密钥,就是因为它们不是公开使用的模型。需要阅读协议,填写资料,然后申请。
打开下面两个项目申请就好了。
https://huggingface.co/pyannote/speaker-diarizationhttps://huggingface.co/pyannote/segmentation
这个申请应该是全自动的,不用担心通不过!
2. 获取百度翻译的密钥
百度大家应该熟悉,这里要用到它的翻译平台。可以通过下面网址上的指导获取。
https://fanyi-api.baidu.com/doc/21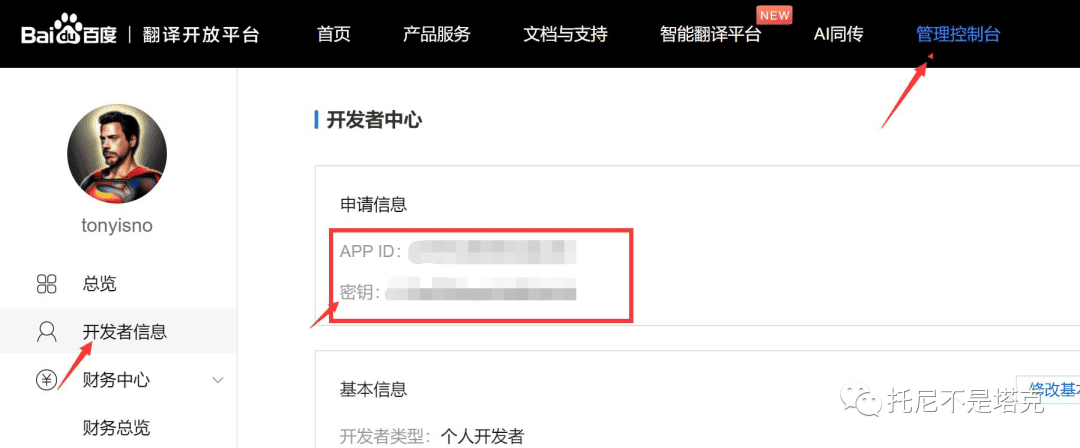
需要开通一个叫“通用文本翻译”的服务,这个服务可以免费使用。
开通之后,在控制台,开发者信息中,找到APPID和密钥记录下来。
3. 获取Colab脚本。
脚本我已经上传到Github上面,找到TonyColab这个项目。
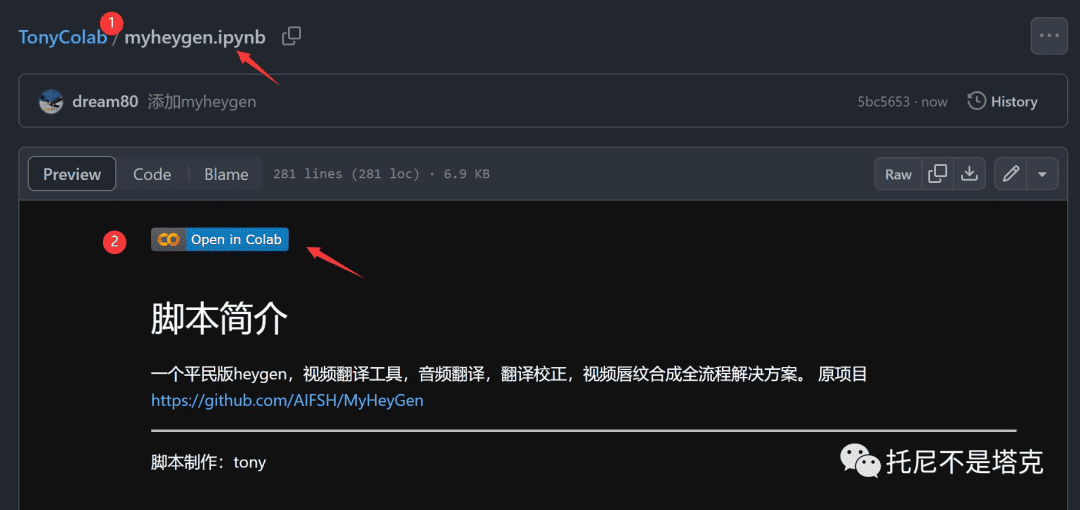
点击myheygen.ipynb ,然后点击Open in Colab 就可以了打开了。打开后会自动调用谷歌的GPU,默认应该是显存为16G的T4。
4. 更改运行时
执行脚本之前,需要先确认一下运行时。查看和设置方式如下。
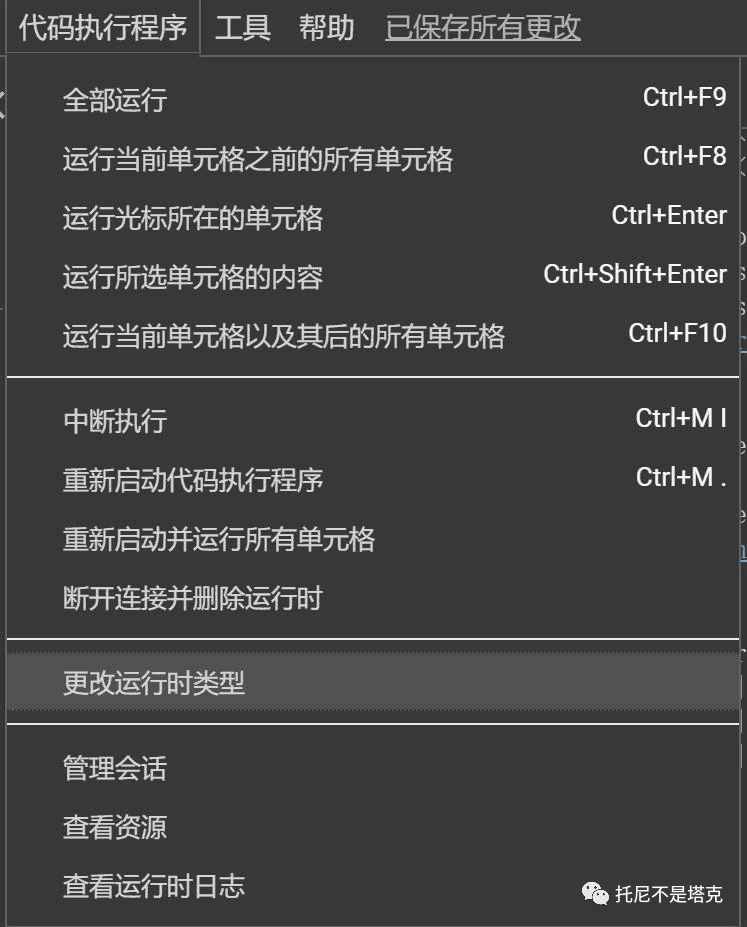
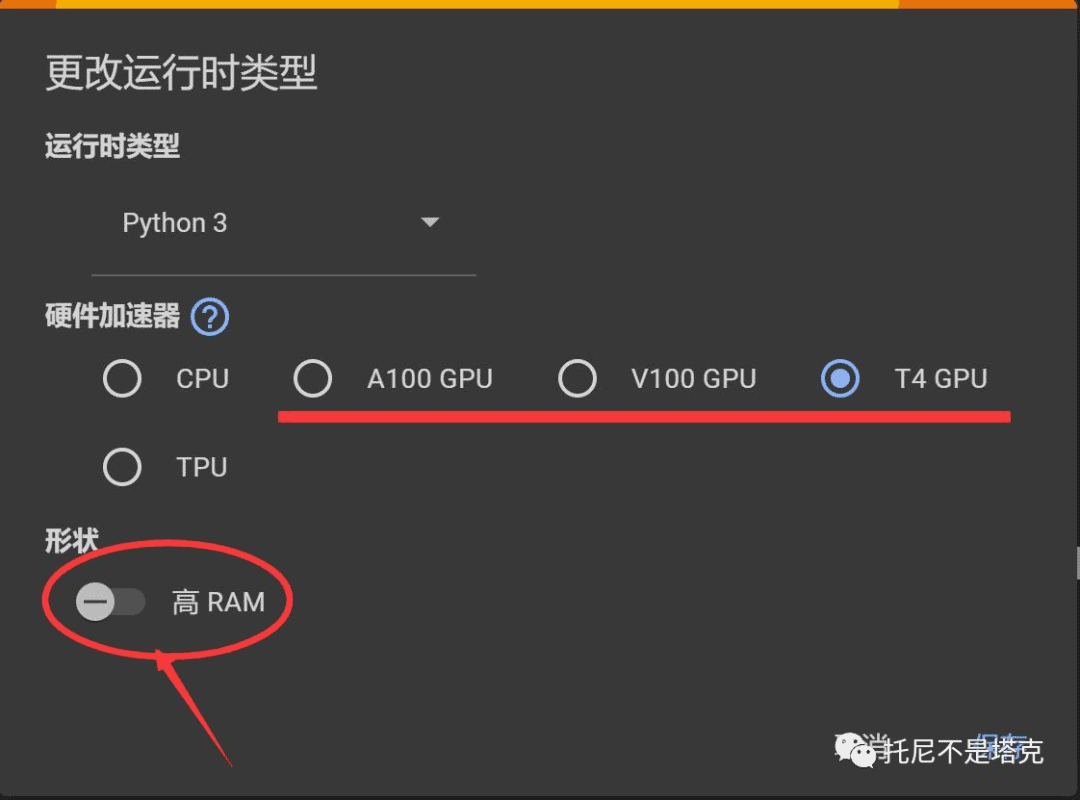
硬件加速器需要选择带GPU的,上图中列出的GPU都可以运行这个项目。
另外一个是记得勾选高RAM,如果内存不够,会运行失败。
5. 挂载云端硬盘
这个项目需要用到十几个模型,需要将这些模型先保存到自己的谷歌云盘里面。然后将谷歌云盘挂载到Colab上面。
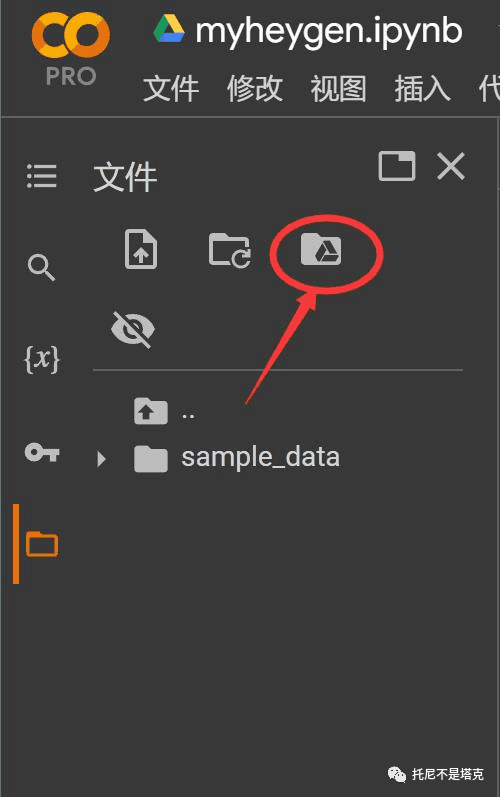
挂载的时候会让你用谷歌账号进行授权,按提示点击就可以了。
6. 修改配置文件。
接下来需要设置一下配置文件,配置完成之后就很简单了。只要点点点就行!
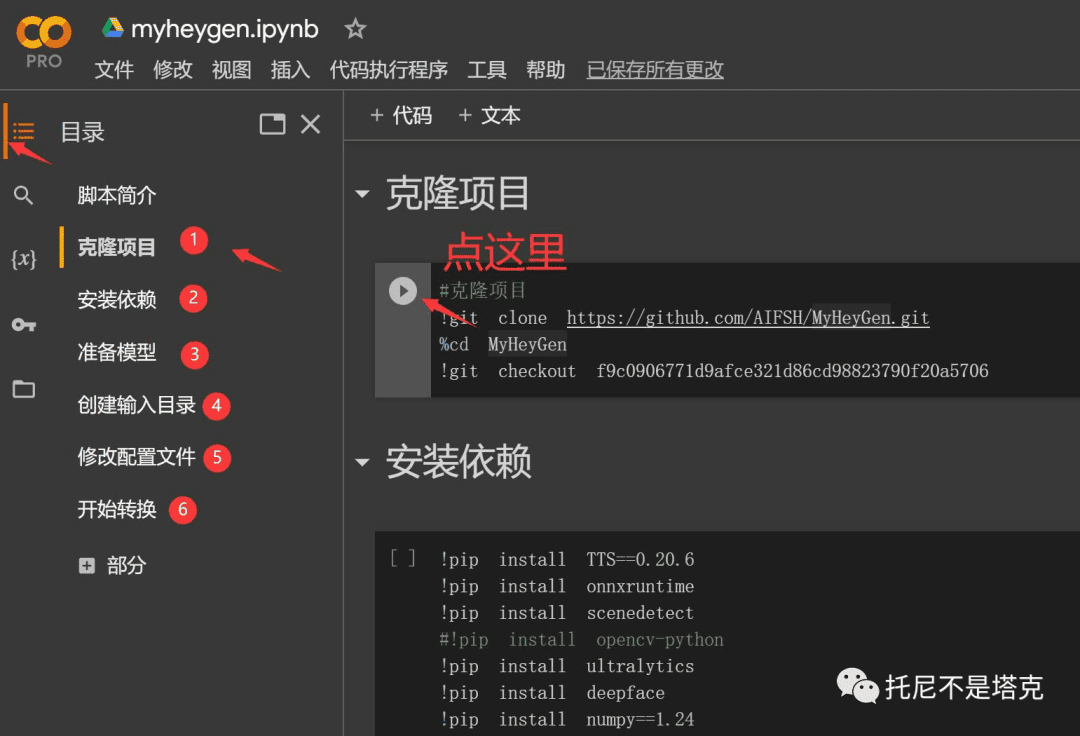
脚本的运行步骤如上,从①点到⑥就结束了。
点击第①步中的播放按钮,就会自动克隆项目代码,自动产生配置文件。
在文件管理里面找到config.json这个文件。
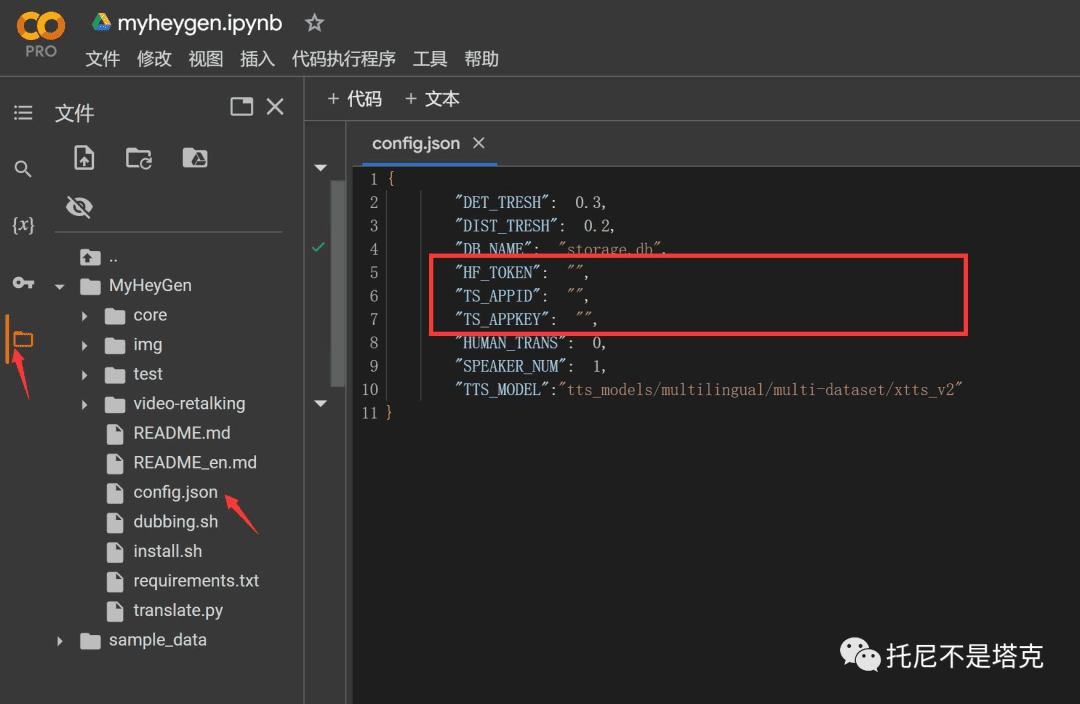
双击打开这个文件,修改三个项。
HF_TOKEN 后面加huggingface上获取到的token
TS_APPID和TS_APPKEY后面加百度翻译上获取到的APPID和密钥。
设置完成之后按Ctrl+S保存。
到这里,所有设置都完成了。
7. 开始制作视频
终于,可以开始搞视频了。
视频制作逻辑是,你先把需要处理的视频上传到est文件里面,命名为src.mp4。然后指定一种语言,比如中文,就可以让视频中的人说中文。
语音转文本,文本翻译,文本转语音,声音克隆,嘴型同步,视频合成。全部一键完成。
运行结束之后会在这个est下面生成一个out_zh.mp4的视频。这个就是结果视频。
如果你还没找到测试视频也没关系,项目自带了一个src.mp4视频,是懂王讲英语的视频。处理完成之后,懂王就能说中文了。
这些说明白之后,就只要在上面的基础上依次运行2,3,4,5,6这些步骤就好了。
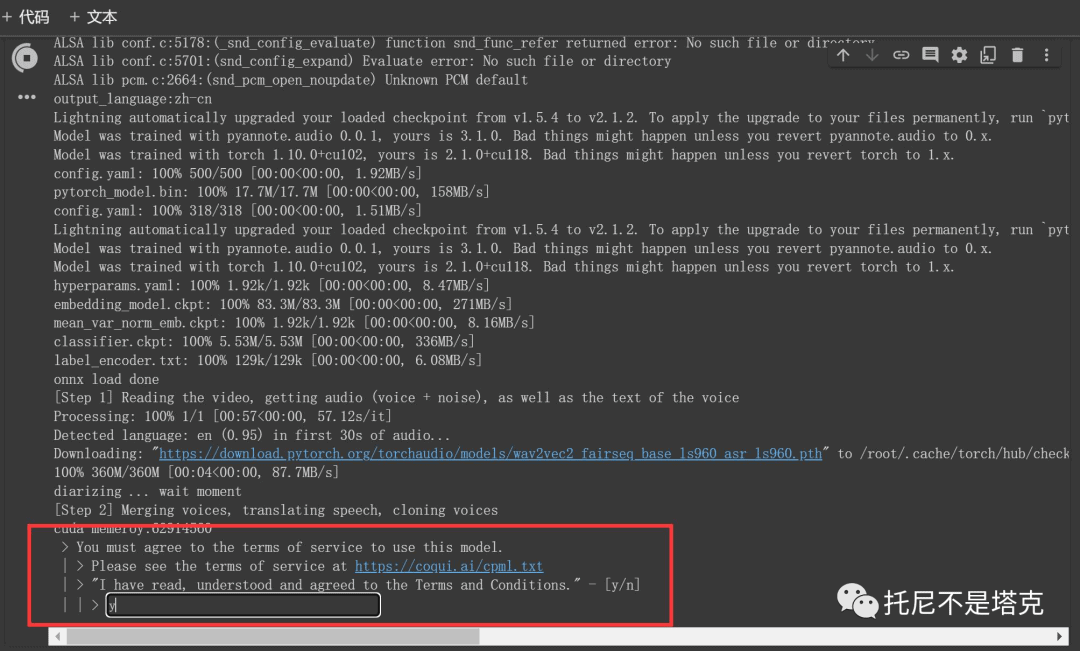
第⑥步运行的时候,中途还会让你确认协议。你只需要输入y然后按回车即可。
8. 查看效果
稍等片刻,制作好的视频就会保存在est文件夹里面。
找到视频,右键下载,就可以在电脑上查看效果了。
从最终的视频来看,声音相似度比较一般,语言翻译和转换是很成功的,视频画面看起来还可以,整一套东西能一键完成也是相当不容易了,不同的对象可能会出现不一样的结果,有的不太像,有的就比较好。
整个架子有了,只要逐个优化,感觉未来可期!
喜欢折腾的可以玩一玩,不喜欢折腾但是又想做视频的直接去Heygen充值就好了。
不管你用哪一种,记得给我点赞!
看这步骤,就知道我没少花时间,哈哈!
本篇文章来源于微信公众号: 托尼不是塔克 喜欢可以搜索关注!